
This blog is the latest post in an ongoing series about GitLab’s journey to build and integrate AI/ML into our DevSecOps platform. The first blog post can be found here. Throughout the series, we’ll feature blogs from our product, engineering, and UX teams to showcase how we’re infusing AI/ML into GitLab.
The GitLab DevSecOps platform now features Machine Learning Model Experiments, which is avaliable to all GitLab users, making GitLab a powerful tool for creating ML models. Organizations can now track the many versions of their ML models within the GitLab user interface, using the open source MLFlow.
What is an ML model?
An ML model is the result of three components: code to extract the patterns from the data, the data where the patterns are extracted from, and the configuration used for both, often called "hyperparameters". Any change to any of these components can lead to changes in the model performance, and keeping track of all of these parts and the results can be challenging. Experiment tracking aims to make sense of this confusion by keeping a record of all of the variations created, along with the artifacts and results of each trial.
MLFlow is a popular open source solution for ML experiment tracking, providing a client to log different model versions and their metadata. However, it puts the cost of deployment and managing its server onto the users.
GitLab makes the tracking process easier not by deploying a managed MLFlow backend, but by being an MLFlow backend itself. This marries the best of both worlds: Data scientists don't need to learn yet another client as their code requires minimal to no changes, while GitLab provides everything else. There is no need to manage a server or to implement user management, so there is no need to configure your artifact storage – this is all provided by the GitLab DevSecOps platform.
ML model experiment features in GitLab 16.0
Watch this overview of the available features in 16.0:
-
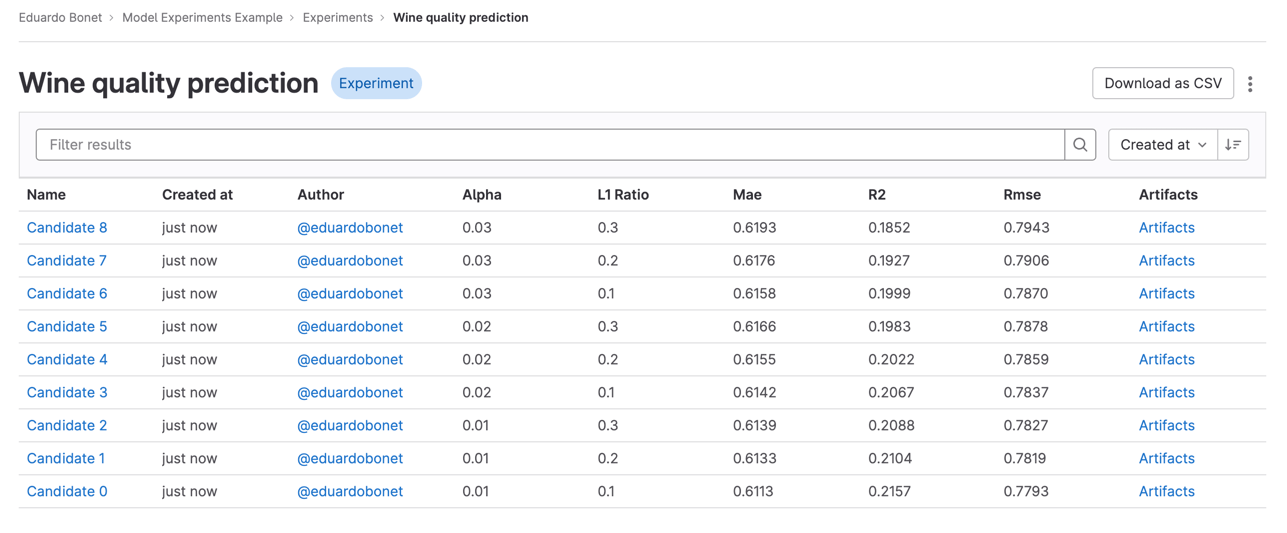
Create experiments and candidates using the MLFlow client: Simply point the MLFlow client to your GitLab project and experiments and runs will be recorded on GitLab, with no additional setup necessary and no need to create a server. Note that MLFlow runs are called "candidates" in GitLab, as each of them is a candidate to become a version of a model.
-
User access management: Experiments are tied to a GitLab project, making it easy to control which users have access to which models.
-
Manage candidates directly on the GitLab UI: Search and explore your logged experiments on GitLab, using the UI you already know.
-
Download candidate data as a CSV: Data scientists that want to explore or create reports on an experiment can download the necessary data as a CSV file.
To get started, refer to the documentation.
More to come
GitLab wants to help you manage the entire lifecycle of your machine learning model from creation to packaging, deployment, and monitoring. For more information on what we are working on, keep an eye on the MLOps Incubation Engineering handbook page and on our YouTube playlist.
Machine Learning Model Experiments is an experimental feature available to all GitLab tiers, and we are looking for feedback so please comment in this issue.
Continue reading our "AI/ML in DevSecOps" series.
Disclaimer: This blog contains information related to upcoming products, features, and functionality. It is important to note that the information in this blog post is for informational purposes only. Please do not rely on this information for purchasing or planning purposes. As with all projects, the items mentioned in this blog and linked pages are subject to change or delay. The development, release, and timing of any products, features, or functionality remain at the sole discretion of GitLab.


